

こんにちは、ヒガシです。
このページではオートエンコーダーを使ってMNISTの画像から各数字の画像が持つ特徴量を2次元マップ上に可視化するということを実演していこうと思います。
それではさっそくやっていきましょう!
オートエンコーダー(Auto Encoder)の概略
まずはオートエンコーダーというものがどんなものなのかを説明します。
オートエンコーダーは次元を圧縮していくエンコーダー部分と、圧縮した次元を増加させていくデコーダー部分で構成されます。
そしてエンコーダーとデコーダーのちょうど境目のところに2次元(別に3次元でも、4次元でも良いですが)の中間層が設けれています。
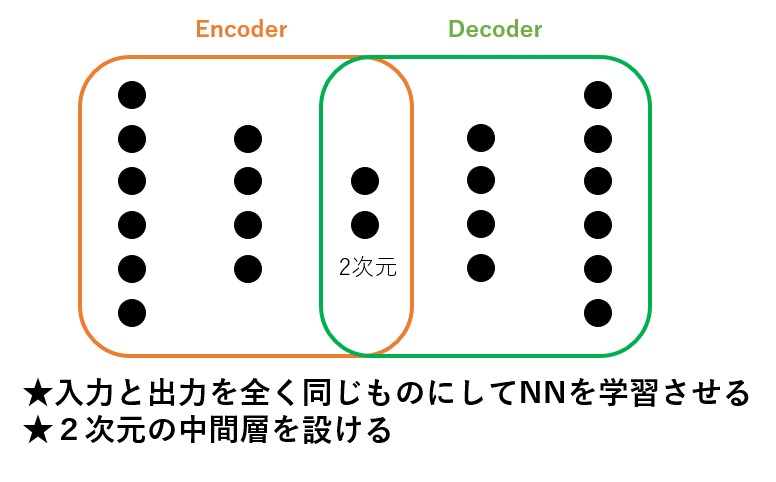
そしてこのニューラルネットワークを、入力と出力がまったく同じデータを使って学習させます。
そうすることによってこの2次元の情報にはデータを説明する情報が凝縮されます。
例えばエンコーダー部分だけを取り出し既知のデータをたくさん入力すれば、入力データがどんなグループに分類できるのかを2次元mapで可視化分析できたり、デコーダー部分だけを取り出せば2次元の情報を適当に与えることで疑似データを大量に生成することが可能です。
前回の記事では、後者であるデコーダー部分を使った疑似データの作成を実演しました。
ということで今回は前者である入力データがどんなグループに分類できるのかを2次元mapで可視化するということを実演していこうと思います。
MNIST画像を使ったオードエンコーダーの学習
ということでまずはオートエンコーダーのモデルを作成していきます。
今回はサンプルデータとして手書き数字データであるMNISTの画像データを使用します。
画像は(28,28)ピクセルで構成されますので、この画像を1次元の784次元にし、オートエンコーダーの入力および出力データとして使用していきます。
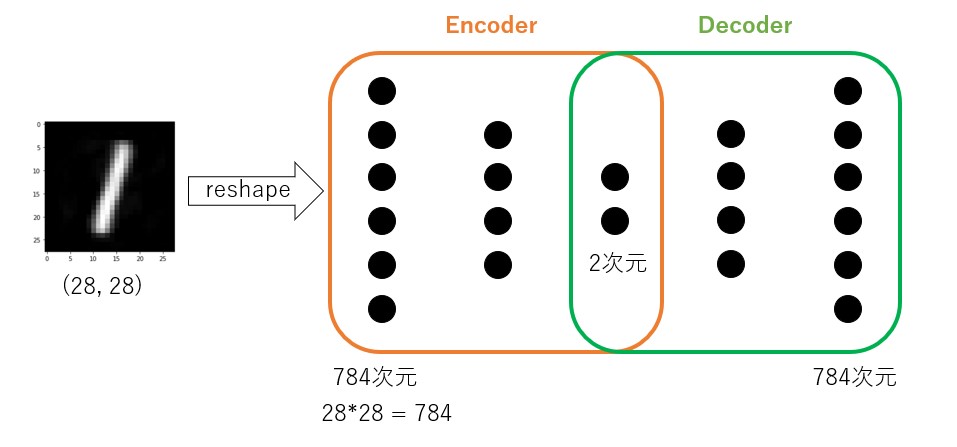
ということで以下がオートエンコーダーモデルの生成プログラムです。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation ,Conv2D, MaxPooling2D,Dropout, Flatten,BatchNormalization
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
import random
# MNISTデータを読込む
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# MNISTデータを加工する
inout_dim = 784
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
#オートエンコーダーモデルの定義
model = Sequential()
model.add(Dense(128, input_dim = inout_dim))
model.add(Activation('relu'))
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dense(2))
model.add(Activation('tanh'))
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dense(inout_dim))
model.compile(loss="mean_squared_error", optimizer=Adam(lr=0.001))
model.summary()
history=model.fit(x_train, x_train, batch_size=32, epochs=50, validation_data = (x_test , x_test))
#学習結果の可視化
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('loss')
plt.xlabel('Epoch')
plt.grid()
plt.legend(['train','test'],loc='upper left')
plt.show()
以下が学習結果です。
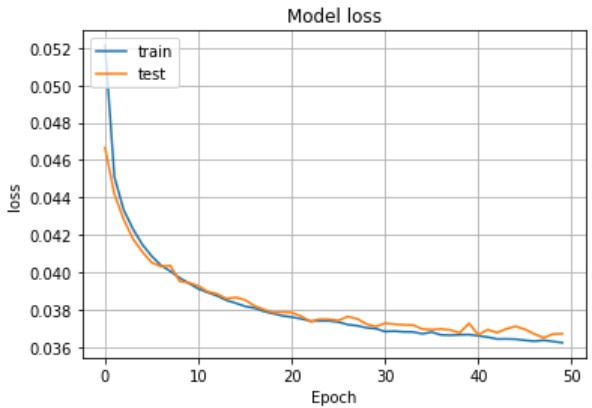
問題なくLossが減っていますね。
ということでモデルの学習は完了です。
学習済みモデルからエンコーダー部分を取り出す
次は先ほど学習させたデータからエンコーダー部分を取り出します。
重み、バイアスの取り出し方は以下で詳細説明していますので参考まで。
【AI】ニューラルネットワークから重み、バイアスを取得する方法!
以下が今回のモデルから重み、バイアスを取り出すコードです。
#デコーダー部分の重み、バイアスを取得する
Enc_W1 = model.layers[0].get_weights()[0]
Enc_b1 = model.layers[0].get_weights()[1]
Enc_W2 = model.layers[2].get_weights()[0]
Enc_b2 = model.layers[2].get_weights()[1]
Enc_W3 = model.layers[4].get_weights()[0]
#エンコーダー部分の計算を実施⇒画像配列にする関数
def calc_encoder(input_data):
L1P = np.dot(input_data,Enc_W1)+Enc_b1
L1P = np.where(L1P<0,0,L1P)
L2P = np.dot(L1P,Enc_W2)+Enc_b2
L2P = np.where(L2P<0,0,L2P)
L3P = np.dot(L2P,Enc_W3)+Enc_b3
L3P = np.tanh(L3P)
return L3P
これでcalc_encoder関数に適当な入力データである784次元の配列を流し込めば、そのデータの特徴を凝縮した2次元のデータが出力されます。
オートエンコーダーを使った特徴量の可視化トライアル
それでは先ほどまでに作成したモデルを使って実際に特徴量の可視化をトライしてみます。
以下がそのサンプルコードです。
#エンコーダーで各画像が持つ特徴量を2次元mapで表す
for i in range(2000):
input_data = x_test[i,:]
L3P = calc_encoder(input_data)
if y_test[i] == 0:
color = 'red'
plt.scatter(L3P[0],L3P[1], color = color)
elif y_test[i] == 1:
color = 'blue'
plt.scatter(L3P[0],L3P[1], color = color)
elif y_test[i] == 2:
color = 'green'
plt.scatter(L3P[0],L3P[1], color = color)
elif y_test[i] == 3:
color = 'yellow'
plt.scatter(L3P[0],L3P[1], color = color)
elif y_test[i] == 4:
color = 'orange'
plt.scatter(L3P[0],L3P[1], color = color)
elif y_test[i] == 5:
color = 'black'
plt.scatter(L3P[0],L3P[1], color = color)
elif y_test[i] == 6:
color = 'pink'
plt.scatter(L3P[0],L3P[1], color = color)
elif y_test[i] == 7:
color = 'purple'
plt.scatter(L3P[0],L3P[1], color = color)
elif y_test[i] == 8:
color = 'gray'
plt.scatter(L3P[0],L3P[1], color = color)
elif y_test[i] == 9:
color = 'brown'
plt.scatter(L3P[0],L3P[1], color = color)
plt.show()
やっていることはMNISTのテスト用画像2000枚を順番にエンコーダーモデルに流し込み、出てきた2次元の特徴量をmatplotlibで散布図化しているだけです。
以下がその結果です。色分けは以下の通りです。
0:’red’ 1:’blue’ 2:’green’ 3:’yellow’ 4:’orange’
5:’black’ 6:’pink’ 7:’purple’ 8:’gray’ 9:’brown’
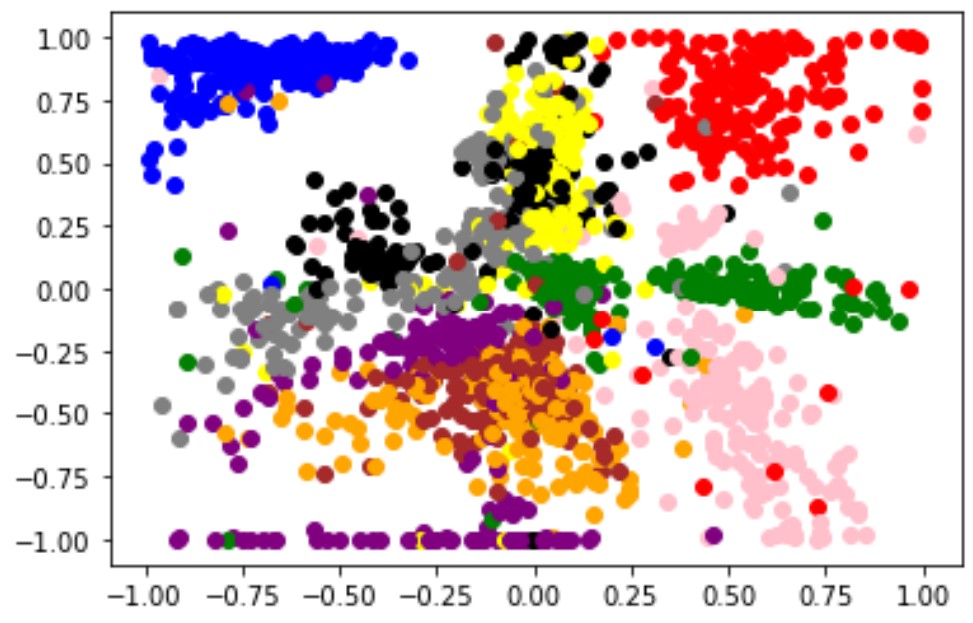
ある程度同じ数字は似たような特徴を持ってかたまっていることがわかると思います。
こんなことをして何がうれしいかと言うと、例えば上の画像を見てもらうと0を表す赤や1を表す青なんかはしっかりと単独の島を形成し、独自の特徴を持っていることがわかると思います。
一方で、4を表すオレンジと9を表す茶色はほぼ重なってしまっていることもわかると思います。確かに改めてよくみると4と9は似た形をしていますよね。
人間だとなかなかこういった似た者同士を定量的に分類するのは難しいですが、上記のような手法をとることで、データを分類したり、データの持つ特徴を説明できたりするようになるのです。
おわりに
ということで今回はオートエンコーダーとMNISTのサンプルデータを使って画像が持つ特徴量を可視化するということをトライアルしてみました。
AI系業務をしていると予測モデルを作るだけでなく、データから何か言えることはないかを問われることも多々あります。
こういったデータ解析手法もぜひ習得しておきましょう!
このブログでは、このようなAIスキルを多数紹介しています。
ぜひ他のページもご覧ください。
それではまた!


コメント