

こんにちは、ヒガシです。
今回は画像分類問題でよく使われるCNNモデルをベースに、ほかの情報も一緒に入力するAIモデルを構築していこうと思います。
具体的には以前紹介した、丸、三角、四角の画像に対して、
入力1:画像データそのもの
入力2:画像内図形の線の太さ、位置、線の明るさ等の情報
出力:図形の分類結果
というAIモデルを構築していこうと思います。
単純に画像だけではなく、ほかの情報も一緒に入力することで予測精度が改善することもあると思いますのでそういった状況で使えるスキルだと思います。
とはいえ今回は精度を改善することが目的ではなく、複数の情報を画像分類モデルに入力するにはどうやったら良いか、を紹介することが目的です。
それではさっそくやっていきましょう!
※今回はKerasを使って構築していきます。
サンプルデータの構築について
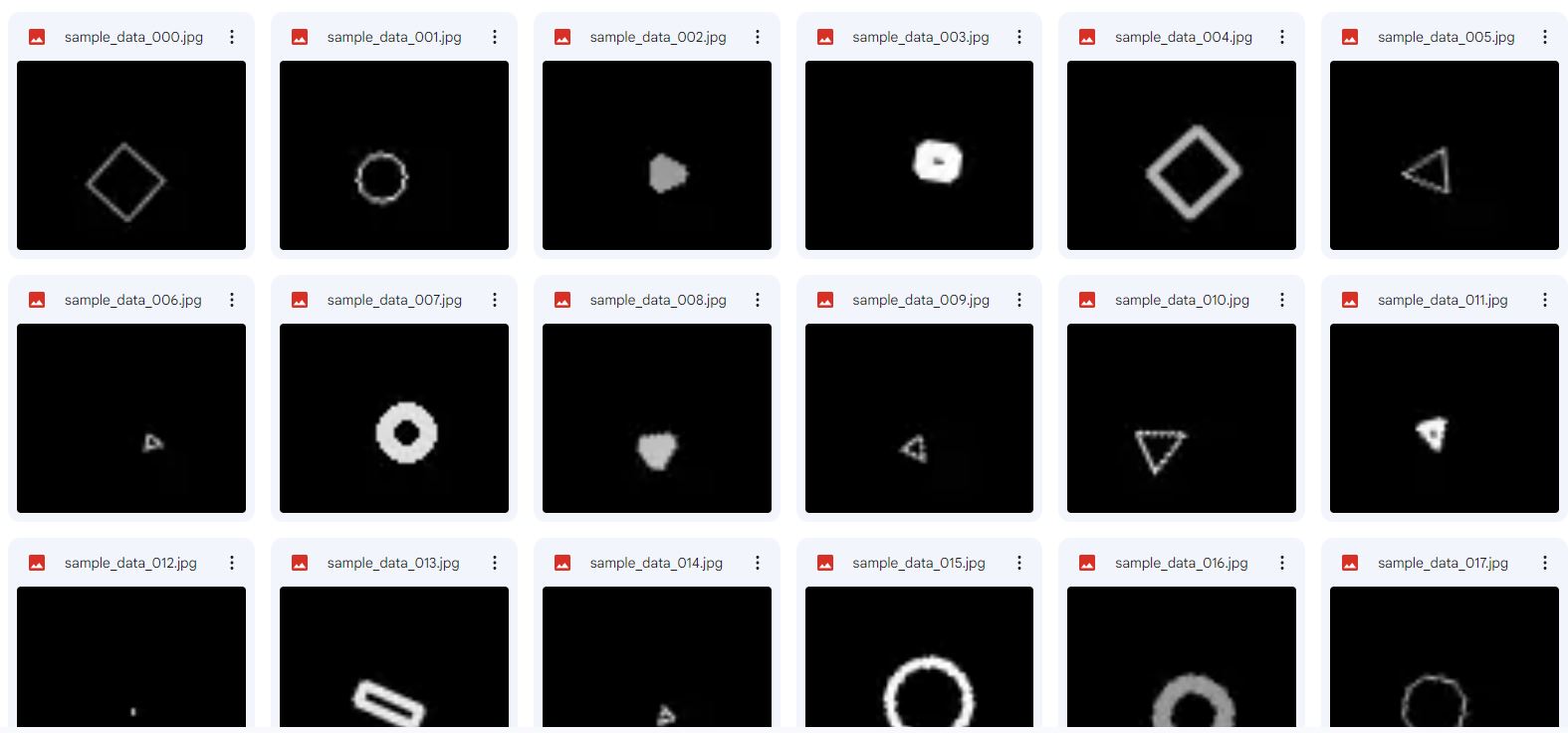
今回も前回紹介したときと同様に、適当に丸、三角、四角の画像を生成していきます。
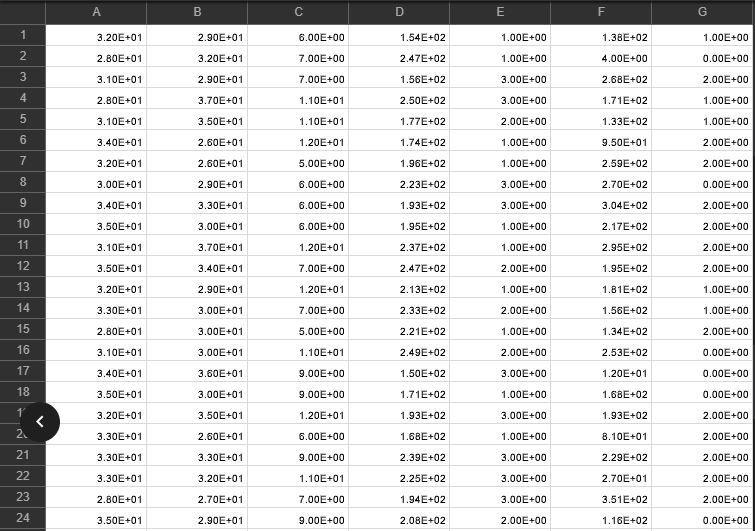
さらにその画像を生成する過程で、図形の位置(X,Y)、サイズ、線の太さ、線の明るさ、図形の回転角度という直接的に図形の形はわからないものの、図形を分類する際のヒントになりそうなものも一緒に保存しておきます。
以下がそのサンプルコードです。
#ライブラリインポート
from PIL import Image
import cv2
import numpy as np
import pandas as pd
import os
import random
import glob
base_dir='CNN_sample'
os.makedirs(base_dir, exist_ok=True)
#作成する画像の枚数
num_pic=800
#画像のサイズ
h=64
w=64
sub_info=[]
for i in range(num_pic):
img=np.zeros((h,w),np.uint8)
x1=random.randint(20,w-30)
y1=random.randint(20,h-30)
x2=random.randint(30,w-20)
y2=random.randint(30,h-20)
size=random.randint(5,12)
b=random.randint(150,255)
thickness=random.randint(1,3)
angle=random.randint(0,359)
rnd=random.randint(0,2)
x=int((x1+x2)/2)
y=int((y1+y2)/2)
if rnd==0:
cv2.circle(img,(x,y),radius=size,color=b,thickness=thickness)
elif rnd==1:
cv2.rectangle(img,(x1,y1),(x2,y2),color=b,thickness=thickness)
else:
cv2.drawMarker(img,(x,y),b,markerType=cv2.MARKER_TRIANGLE_UP,markerSize=size,thickness=thickness)
ROT=cv2.getRotationMatrix2D(center=(int(w/2),int(h/2)),angle=angle,scale=1)
img=cv2.warpAffine(img,ROT,dsize=(w,h))
sub_info.append([x,y,size,b,thickness,angle,rnd])
cv2.imwrite(base_dir+'/sample_data_'+str(i).zfill(3)+'.jpg', img)
np.savetxt(base_dir+'/sub_info.csv', sub_info, delimiter=",")
これを実行するとCNN_Sampleフォルダに800枚の画像と図形の情報+図形が何なのかを保存したcsvファイルが保存されているはずです。
★生成した画像一覧
★情報が入ったcsvファイル
生成したデータをAI入力用に加工する
次は先ほど生成したデータをAIが読み取れる形に加工していきましょう。
以下がそのサンプルコードです。
pics=glob.glob(base_dir+'/sample_data*.jpg')
sub_info=pd.read_csv(base_dir+'/sub_info.csv', header=None).values
#入出力データを入れる箱を準備
Xdata1=[]
Xdata2=[]
Ydata=[]
i=0
for pic in pics:
#画像を1枚読み込む
img = Image.open(pic)
#輝度を正規化する
img=np.array(img)/255
#読み込んだ画像を入力の箱に加える
Xdata1.append(img)
#sub_infoも入力データとして整える
Xdata2.append(sub_info[i,:-1])
#画像に対応する出力データ(分類結果を表すデータ)を作成する
#円だったら(1,0,0)四角なら(0,1,0),三角なら(0,0,1)
Y=np.zeros(3,np.uint8)
Y[int(sub_info[i,-1])]=1
#出力データの箱に入れる
Ydata.append(Y)
i+=1
Xdata1=np.array(Xdata1)
Xdata2=np.array(Xdata2)/200
Ydata=np.array(Ydata)
#データを学習用、評価用に分割する
validation_split_rate=0.2
Xdata1_train=Xdata1[:int(len(Xdata1)*(1-validation_split_rate))]
Xdata1_valid=Xdata1[-int(len(Xdata1)*(validation_split_rate)):]
Xdata2_train=Xdata2[:int(len(Xdata2)*(1-validation_split_rate))]
Xdata2_valid=Xdata2[-int(len(Xdata2)*(validation_split_rate)):]
Ydata_train=Ydata[:int(len(Ydata)*(1-validation_split_rate))]
Ydata_valid=Ydata[-int(len(Ydata)*(validation_split_rate)):]
※本来データの正規化、標準化はまじめにやった方がよいのですが、今回は複数入力のモデルを作ることが目的なので適当にやっています。
これでXdata1***に画像としての情報が、Xdata2***に画像内の図形の基礎情報が格納されています。
また、Ydata***には画像内の図形が何なのかを表す情報が入っています。
複数入力を持つ画像分類CNNモデルの構築
それでは本題である複数入力を持つ画像分類CNNモデルを構築していきましょう!
以下がそのサンプルコードです。
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D,Dropout, Flatten,concatenate, BatchNormalization
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
#画像を入力してCNNを構築
input1 = Input(shape=(64,64,1))
model1 = Conv2D(32, (3, 3), padding='same', activation='relu')(input1)
model1 = BatchNormalization()(model1)
model1 = MaxPooling2D((2, 2))(model1)
model1 = Conv2D(32, (3, 3), activation='relu')(model1)
model1 = BatchNormalization()(model1)
model1 = MaxPooling2D((2, 2))(model1)
model1 = Conv2D(16, (3, 3), activation='relu')(model1)
model1 = BatchNormalization()(model1)
model1 = MaxPooling2D((2, 2))(model1)
model1 = Conv2D(8, (3, 3), activation='relu')(model1)
model1 = BatchNormalization()(model1)
model1 = MaxPooling2D((2, 2))(model1)
model1 = Flatten()(model1)
model1 = Model(inputs=input1, outputs=model1)
#数値データを入力してMLPモデルを構築
input2 = Input(shape=(6,))
model2 = Dense(25, activation='relu')(input2)
model2 = Model(inputs=input2, outputs=model2)
#CNNの出力(model1)とMLPの出力(model2)を結合してMLP化(model)する
model = concatenate([model1.output,model2.output])
model = Dense(32, activation='relu')(model)
model = Dropout(0.5)(model)
model = Dense(3, activation='softmax')(model)
model = Model([model1.input, model2.input],outputs=model)
model.compile(loss='categorical_crossentropy',optimizer=Adam(lr=0.001),metrics=['accuracy'])
model.summary()
#学習開始
history=model.fit([Xdata1_train,Xdata2_train],Ydata_train,batch_size=32,epochs=100,validation_data=([Xdata1_valid,Xdata2_valid],Ydata_valid))
#学習結果の可視化
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.grid()
plt.legend(['Train','Validation'],loc='upper left')
plt.show()
こいつを実行すると以下の結果が出力されました。
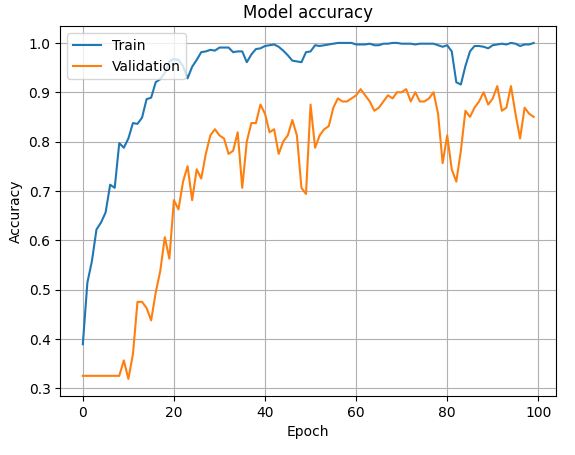
問題なく学習できていそうですね。
まとめ
ということで今回はKerasのFunctionAPIモデルを使って、複数の入力(画像+1次元の情報データ)を入力として画像分類を行うモデルの構築を実演してみました。
このAPI機能を使えばどんな複雑なモデルも自由自在に作れるようになります。
ぜひ、いろいろなモデルを自作して練習してみましょう!
それではまた!


コメント