


この記事ではpython-openCVを使って、以下のようにカラム形式で出力されたテキスト輝度データを画像にする方法をご紹介します。
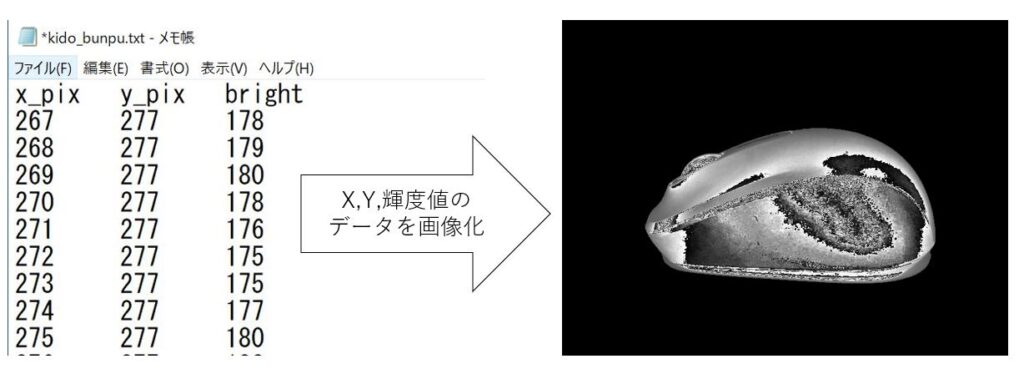
なお、今回使用するテキストデータは前回の記事にて作成したものです。
基本的には前回記事の逆を実行していくことになります。
この記事の内容を詳細に理解したい人は、まずは前回記事から見ていただけると嬉しいです。
それではさっそくやっていきましょう。
カラム形式テキストデータを画像化する方法
さっそくですが、以下がサンプルコードです。
#ライブラリインポート
import cv2
import numpy as np
#輝度データの読み込み
kido=np.loadtxt('kido_bunpu.txt',np.uint32, skiprows=1)
x_max=np.amax(kido[:,0])
y_max=np.amax(kido[:,1])
pic=np.zeros((y_max+1,x_max+1))
#データの画像化
for i in range(len(kido)):
x=kido[i,0]
y=kido[i,1]
z=kido[i,2]
pic[y,x]=z
cv2.imwrite('output.jpg',pic)
今回はこのコードを実行するフォルダ内にkido_bunpu.txtという名前で輝度データが保存されていることを想定して書いてきます。
また、出力された画像はこれまた同じフォルダにoutput.jpgという名前で出力されます。
サンプルコードの中身を解説
先ほどのコードでやっていることは以下の通りです。
①テキストファイルを読み込む
②データ内のX,Yの最大値から画像サイズとなる配列を作成
(このとき配列内データは全部ゼロ)
③①で読み込んだデータを②の配列に埋め込んでいく
④③で作った配列を画像化
この③のところは少しイメージしにくいと思いますので画像で説明しると以下のような感じですね。
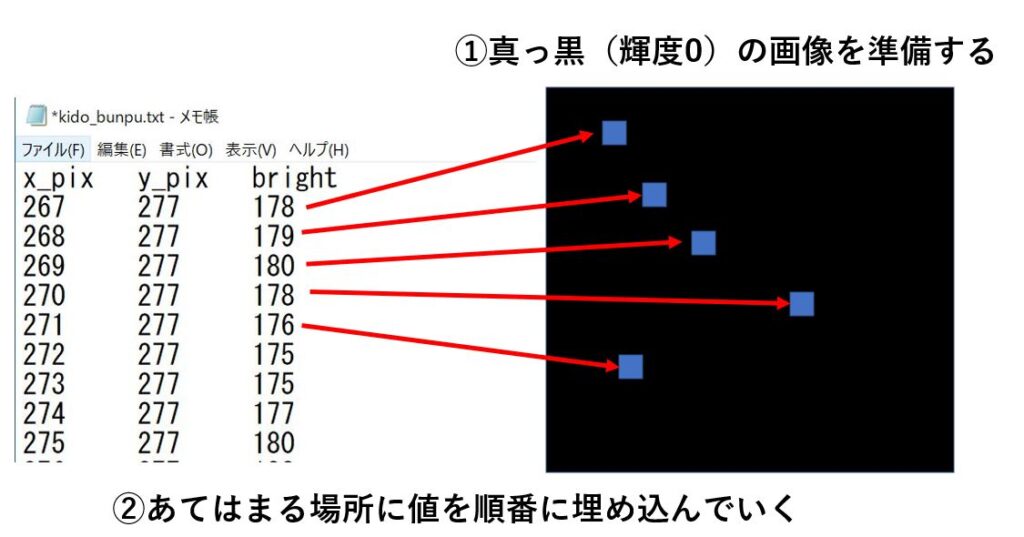
この方法で作成された画像と前回の記事で用いた画像は一致していることが確認できましたので、問題なくテキストから画像を作成できていると思われます。
おわりに
というわけで今回はpython-openCVを使って、カラム形式のテキスト輝度データから白黒画像を作成する方法をご紹介しました。
データを可視化したいときなどにぜひご活用ください。
このように、私のブログでは様々なプログラミングスキルを紹介しています。
今は仕事中で時間がないかもしれませんが、ぜひ通勤時間中などに他の記事も読んでいただけると嬉しいです。
⇒興味をもった方は【ヒガサラ】で検索してみてください。
確実にスキルアップできるはずです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント