


この記事では、2つの配列の対応関係を維持したまま、配列内要素をシャッフルする方法をご紹介していきます。
機械学習の教師データ作成の際に役立つスキルです。
ぜひやり方を覚えておましょう。
なお、今回の記事で用いる基礎的なスキルは以下の記事内でご紹介しています。
pythonにあまり詳しくない人は、こちらからご覧ください。
前置きはこのくらいにして、本題に入っていきましょう。
事前準備:2つの配列を作成
対応関係を維持した状態で2つの配列をシャッフルする方法をご紹介するうえで、まずは2つの配列がなければ話になりません。
というわけで今回は以下の2つのテキストデータを配列として読み込むことにします。
〇配列1
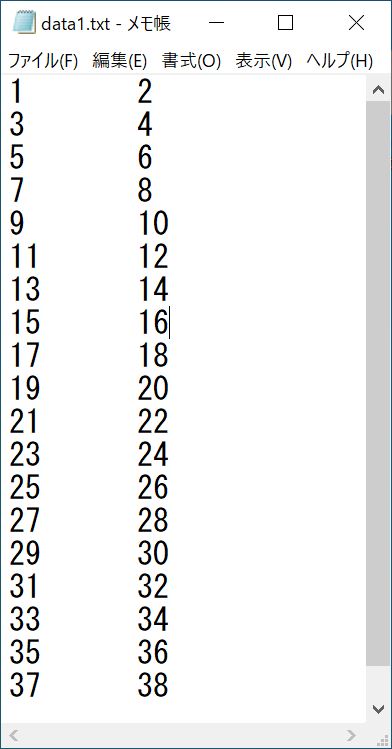
〇配列2

基本的に配列2は配列1の各要素を10倍しただけです。
シャッフル後にこれらの対応関係が崩れていないかよく確認してみてください。
対応関係を維持した状態で2つの配列をシャッフルする方法
事前準備がおわったところで、実際のシャッフル作業に移りましょう。
以下がそのサンプルコードです。
import numpy as np
import random
data1=np.loadtxt('data1.txt',np.uint16)
data2=np.loadtxt('data2.txt',np.uint16)
for i in range(100):
rnd1=random.randint(0,len(data1))
rnd2=random.randint(rnd1,len(data1))
data1=np.append(data1,data1[rnd1:rnd2],0)
data1=np.delete(data1,np.s_[rnd1:rnd2],0)
data2=np.append(data2,data2[rnd1:rnd2],0)
data2=np.delete(data2,np.s_[rnd1:rnd2],0)
np.savetxt('shuffle1.txt', data1, fmt="%.0f")
np.savetxt('shuffle2.txt', data2, fmt="%.0f")
※配列内にデータがたくさんある場合は、コード中のfor文繰り返し回数を増やしておきましょう。
このコード中でやっていることをざっくり説明すると以下の通りです。
①さきほど紹介した2つの配列を読み込む
②乱数をつかって2つの配列をシャッフル
③シャッフル後の配列をテキストデータとして保存
②の工程で配列1と配列2に対して同じ乱数を使用することで、対応関係を維持した状態でのシャッフルが可能になります。
※先ほどもご紹介しましたが、理屈がよくわからない方は以下の記事をご参考ください。
【python】配列内要素の順番をランダムに並べ替える方法!
いずれにせよ、これで配列がシャッフルできているはずです。
結果を確認してみましょう。
⇒シャッフル後の配列を保存したテキストデータには、以下のデータが出力されていました。
〇シャッフル後の配列1
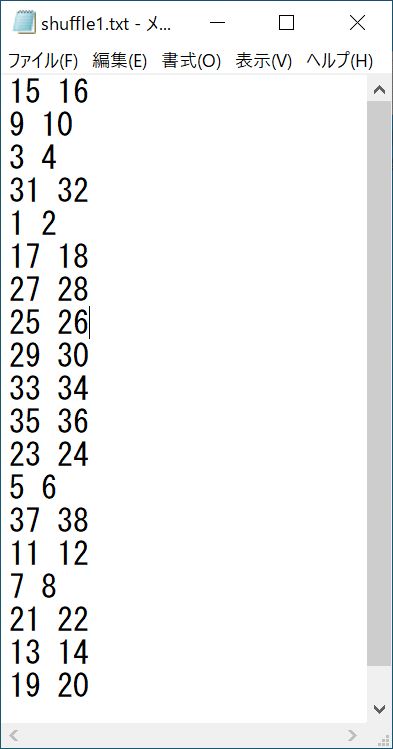
〇シャッフル後の配列2
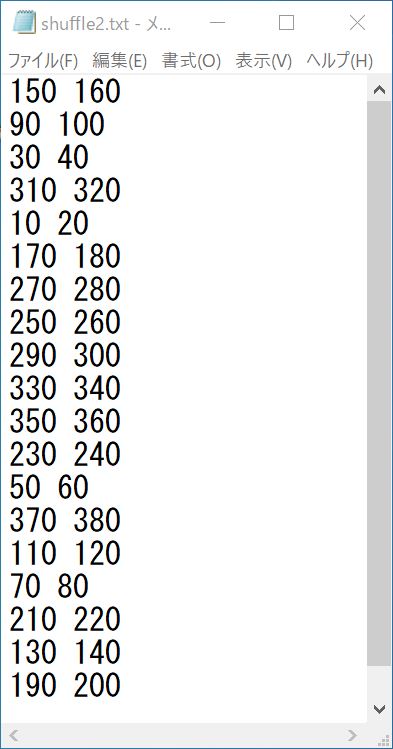
縦にならんでいて見にくいかもしれないので、横並びても載せておきます。
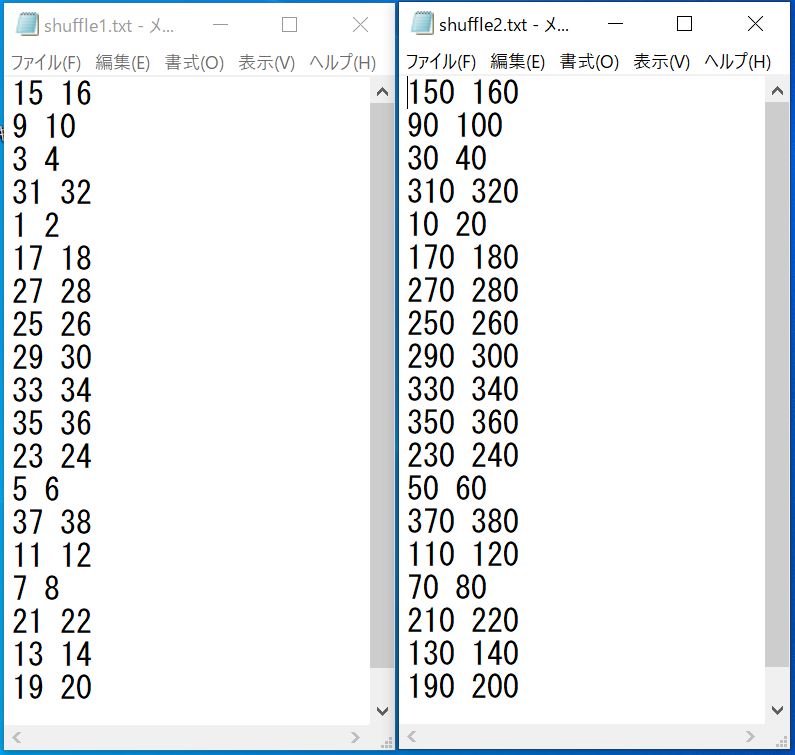
しっかりと右の配列は左の配列の数値×10になっていますね。
問題なく対応関係を維持した状態で2つの配列データをシャッフルできました。
おわりに
というわけで今回はpythonで2つの配列の対応関係を維持したまま、配列内要素をシャッフルする方法をご紹介しました。
AIの教師データを作成する際などにぜひご活用ください。
ぜひ習得しておきましょう!
(実はもっと簡単な方法もありますので、興味がある人は調べてみましょう。)
このように、私のブログでは様々なプログラミングスキルを紹介しています。
今は仕事中で時間がないかもしれませんが、ぜひ通勤時間中などに他の記事も読んでいただけると嬉しいです。
⇒興味をもった方は【ヒガサラ】で検索してみてください。
確実にスキルアップできるはずです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント