

こんにちは、ヒガシです。今回もAIモデルに関するお話です。
AIを実運用していると、
「精度が高いモデルを構築することはできたんだけど、実際に製品へ搭載するには計算コストが高すぎて載せられない。」
なんてことは良くある話です。
というわけでこのページでは、構築済みのAIモデルを縮退化(つまり軽量化)したAIモデルを新たに構築する、という作業を実演してみようと思います。
なお、縮退化モデルを構築する際は、縮退化前のモデルを構築する際に使用したデータは使用できないことを前提に話を進めていきます。
それではさっそくやっていきましょう。
縮退化前のモデルを準備する
縮退化作業を実演するにあたって、まずは縮退化前のモデルがなければ話になりません。
というわけでまずはそれを構築しましょう。
◆データの読み込み
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
data_file='sample_data.csv'
data=pd.read_csv(data_file).values
Xdata=data[:,:4]
Ydata=data[:,-1]これでXdataに入力として4つのデータ、Ydataに出力として1つのデータが格納されています。
※データの詳細は本筋から外れるので割愛しますが、適当なSIN波を合成したようなデータが入っています。
◆縮退化前のモデルを構築
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, Dropout
from tensorflow.keras.optimizers import Adam
#ニューラルネットワーク構成⇒学習まで
model = Sequential()
model.add(Dense(500, input_dim=4))
model.add(Dense(500))
model.add(Dense(500))
model.add(Dense(1))
model.compile(loss="mean_absolute_error", optimizer=Adam(lr=0.001))
model.summary()
history=model.fit(Xdata,Ydata,batch_size=16,epochs=100,validation_split=0.2)
#学習結果のプロット
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
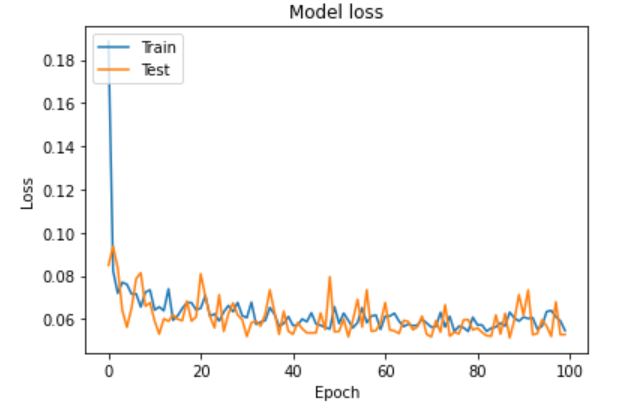
結果は以下の通りで問題なく学習が進みました。
というわけで、これで以下のようにDense500が3層あるモデルを構築することができました。

今回はこのモデルだけを使って縮退化モデルを再構築してみようと思います。
先述した通り、縮退化モデルを構築する際は縮退化前モデルを構築する際に使用したデータ(今回でいうXdata,Ydata)は使用できない前提で話を進めていきます。
縮退化モデル用のデータを生成する
先ほども述べたように、今回はベースとなるモデル(縮退化前)を構築する際に使用したデータ(今回でいうXdata,Ydata)は使用できない前提です。
では縮退化モデルを学習させる際はどうすればよいでしょうか?
その答えは、縮退化前のモデルに入力データをいくつも流し込み、出てきた出力データと紐づけてデータを再生成するという手法です。
要はすでにあるAIモデル(縮退化前)に新たにデータを生成させてやろう、という考えです。
実際にそれをやってみます。
◆縮退化モデル用のデータ再生成
※先ほどの続きなので縮退化前モデルは変数modelに格納されています。
import random
#ベースモデル構築時のデータmaxminを指定(外挿領域を使わないようにする)
Xinput_min=[0,0,0,0]
Xinput_max=[1,1,1,1]
#縮退モデル用のデータ構築
Xdata2=[]
Ydata2=[]
#構築するデータセットの数
num_data=1000
num_Xdim=4
for i in range(num_data):
inputdata=[]
for j in range(num_Xdim):
inputdata.append(random.uniform(Xinput_min[j], Xinput_max[j]))
inputdata=np.array(inputdata)
outputdata=model.predict(np.array([inputdata]))
Xdata2.append(inputdata)
Ydata2.append(outputdata)
Xdata2=np.array(Xdata2)
Ydata2=np.array(Ydata2)上記コードでやっていることは
①指定範囲内で入力データを作成
②①のデータを既存モデルに投入
③投入した入力データ、出てきた出力データを保存
という作業を1000回繰り返しています。
これでXdata2, Ydata2という変数に縮退化モデル用の学習データが格納されています。
縮退化モデルを構築する
事前準備はここまで。
先ほど作成したデータを使って縮退化モデルを構築しましょう。
以下のコードで構築します。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, Dropout
from tensorflow.keras.optimizers import Adam
#ニューラルネットワーク構成⇒学習まで
model_shulink = Sequential()
model_shulink.add(Dense(20, input_dim=4))
model_shulink.add(Dense(20))
model_shulink.add(Dense(1))
model_shulink.compile(loss="mean_absolute_error", optimizer=Adam(lr=0.001))
model_shulink.summary()
history=model_shulink.fit(Xdata2,Ydata2,batch_size=16,epochs=100,validation_split=0.2)
ベースとなるモデルはDense500の3層でしたが、今回はDense20
の2層まで縮退化してみました。
これでmodel_shulinkに縮退化後のモデルが格納されています。
縮退化前のモデルと縮退化後のモデルの精度比較
先ほど構築したモデルの精度を確認してみましょう。
やり方としては、縮退化モデルを構築する際に使用した入力データを、縮退化前のモデル、縮退化後のモデルそれぞれに流し込み、出てきた出力結果を比較し両者が一致していることを確認します。
以下がそのコードです。
base_out=model.predict(Xdata2)
shuling_out=model_shulink.predict(Xdata2)
plt.scatter(base_out,shuling_out)
plt.ylabel('Origginal_Model_Output')
plt.xlabel('Shulink_Model_Output')
こいつを実行すると以下の結果が出力されました。
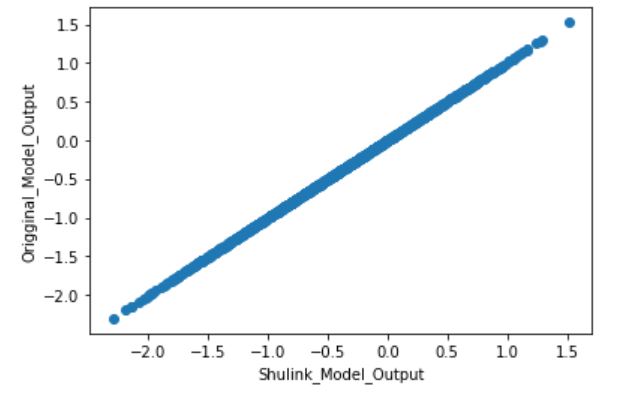 問題なく縮退化前後で出力結果が一致していますね。
問題なく縮退化前後で出力結果が一致していますね。
おわりに
というわけで今回は既存のAIモデルだけを使って、そのモデルの縮退化モデルを再構築する方法をご紹介しました。
今回はそもそも簡単なデータを使っているので非常に高精度に再現できましたが、だいたいこうはうまくいかないので縮退化後の精度もよく確認しながら進めることをオススメします。
このように、私のブログでは様々なスキルを紹介しています。
今は仕事中で時間がないかもしれませんが、ぜひ通勤時間中などに他の記事も読んでいただけると嬉しいです。
⇒興味をもった方は【ヒガサラ】で検索してみてください。
確実にスキルアップできるはずです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント