

こんにちは、ヒガシです。
このページでは、前回の記事にて作成した画像分類AIの構築練習用画像を用いて、実際の画像分類AIモデル(CNNモデル)を構築してみようと思います。
この記事の流れを把握することによって、自前の画像を使って画像分類AIを構築する方法を理解できるはずです。
それではさっそくやっていきましょう!
画像分類AI構築用サンプル画像について
今回は以下に示すように丸、四角、三角が描かれた画像を使用します。位置やサイズ、回転角度をランダムに変更しながら画像を生成し、それぞれの図形ごとにフォルダ分けされているという状態です。
・丸画像のサンプル

・四角画像のサンプル

・三角画像のサンプル

詳細については以下の記事にて解説していますので、興味があれば以下もあわせてご覧ください。
【Python】画像認識系AIモデルの構築練習用サンプル画像作成コード
というわけで今回は、上記の画像を入力することによって、そこに描かれている図形の形(丸 or 四角 or 三角)を答えてくれる画像分類AIモデルを構築していこうと思います。
※使用する画像はカラー画像ですが、図形の形を答えるだけなので今回はモノクロ画像に変換した後にAIに与えるようにします。
準備した画像データの前処理
それでは実際の画像分類AIモデルの構築作業に入っていきましょう!
まずはデータの前処理から行います。
先述した通り、今回画像が保存されているフォルダ構成は以下の通りです。
プログラム実行フォイル
img_folder(画像保存先の親フォルダ)
ー01_img_cir(円画像の保存フォルダ)
ー02_img_rec(四角形画像の保存フォルダ)
ー03_img_cir(三角形画像の保存フォルダ)
この前提でデータの前処理を行います。
以下がそのプログラムです。
#ライブラリインポート
from PIL import Image
import numpy as np
import glob
#親フォルダを指定
base_forder='img_folder'
#親フォルダ内の子フォルダのパスを取得
dirs=sorted(glob.glob(base_forder+'/*'))
#入出力データを入れる箱を準備
Xdata=[]
Ydata=[]
#子フォルダごとに処理を行う
for i in range(len(dirs)):
#子フォルダ内の全画像のパスを取得する
pics=sorted(glob.glob(dirs[i]+'/*.jpg'))
#子フォルダ内の全画像に対して処理を開始する
for j in range(len(pics)):
#画像を1枚読み込む
img = Image.open(pics[j])
#輝度を正規化する
img=np.array(img)/255
#カラー画像からモノクロ画像に変換する(カラーで扱いたい場合はここはなしでOK))
img=(img[:,:,0]+img[:,:,1]+img[:,:,2])/3
#読み込んだ画像を入力の箱に加える
Xdata.append(img)
#上の画像に対応する出力データ(分類結果を表すデータ)を作成する
#円だったら(1,0,0)四角なら(0,1,0),三角なら(0,0,1)
Y=np.zeros(3,np.uint8)
Y[i]=1
#出力データの箱に入れる
Ydata.append(Y)
#作成したデータをnumpy配列に変換する
Xdata=np.array(Xdata)
Ydata=np.array(Ydata)
print(Xdata.shape)
print(Ydata.shape)
これで前処理が完了です。
最後の2行で、入出力それぞれのデータサイズを表示しています。
ここで入力が
(画像の総枚数、画像の縦サイズ、画像の横サイズ)
出力が
(画像の総枚数、分類する際の種類数)
になっていればOKです。
入出力データをシャッフル⇒学習&評価に分割する
先ほどまでに構築したデータは円、四角、三角と順番に処理していきましたので、データが偏っている状態です。
この状態でデータを学習用、評価用に分けてしまうと学習用は円と四角ばかり、評価用は三角ばかりになりますのでまずは入出力の対応関係を保ったまま、データの並びをシャッフルします。
そしてシャッフル後にデータを学習用、評価用に分割します。
その一連の作業プログラムは以下の通りです。
#入力と出力の対応関係を維持したままシャッフル
import random
num_data=len(Xdata)
shaffle_list=random.sample(range(0,num_data),num_data)
Xdata=Xdata[shaffle_list]
Ydata=Ydata[shaffle_list]
#入出力データを学習用、評価用に分割する
validation_split_rate=0.2
X_train=Xdata[:int(len(Xdata)*(1-validation_split_rate))]
X_vali=Xdata[-int(len(Xdata)*(validation_split_rate)):]
Y_train=Ydata[:int(len(Ydata)*(1-validation_split_rate))]
Y_vali=Ydata[-int(len(Ydata)*(validation_split_rate)):]今回は学習用:評価用=8:2で分割しました。
割合を変更したい場合はvalidation_split_rateを調整すればOKです。
これですべてのデータ前処理が完了です。
画像分類AIモデルを構築する
それでは本題である画像分類AIモデルを構築していきましょう。
今回はCNNとMLPを組みあわせたモデルを構築してみました。
以下がそのプログラムです。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation ,Conv2D, MaxPooling2D,Dropout, Flatten,BatchNormalization
from tensorflow.keras.optimizers import Adam
#モデルの定義
model = Sequential()
model.add(Conv2D(128, (3, 3), padding='same',input_shape=(128, 128,1), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(3, activation='softmax'))
#モデルコンパイル
model.compile(loss='categorical_crossentropy',optimizer=Adam(lr=0.001),metrics=['accuracy'])
model.summary()
#学習開始
history=model.fit(X_train,Y_train,batch_size=128,epochs=300,validation_data=(X_vali,Y_vali))
#学習結果の可視化
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.grid()
plt.legend(['Train','Validation'],loc='upper left')
plt.show()
これでだいたい17万くらいのパラメータを持つモデルですね。
また、学習結果をグラフとして可視化するプログラムを記述しています。
画像分類AIの学習結果確認
それでは実際に学習させてみましょう。
先ほどのプログラムを実行すると学習が開始し、完了するのに数分時間がかかります。
実行後は以下の結果が出力されました。
青線が学習用データの正解率、オレンジが評価用データの正解率です。
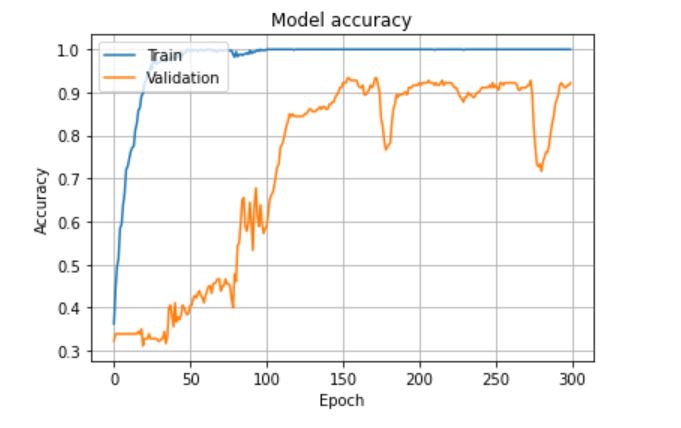
学習用はほぼ完ぺきに学習できていますね。
評価用も90%以上の正解率になっているようです。
学習済みモデルを実際に使ってみる
それでは先ほど学習したモデルに実際に画像を入力してみましょう。
以下がそのサンプルコードです。
#四角形画像が入っているフォルダを指定する
imgs=sorted(glob.glob('img_folder/02_img_rec/*.jpg'))
#四角形画像100枚をテストしてみる
for i in range(100):
#一枚の画像を読み込む
img=Image.open(imgs[i])
#データの前処理(学習する際にやった前処理を同じことをする)
img=np.array(img)/255
img=(img[:,:,0]+img[:,:,1]+img[:,:,2])/3
#AIモデルにデータを入れる
pred=model.predict(np.array([img]))
#結果を出力する
max_index=np.argmax(pred)
label=['circle','square','triangle']
print('Img_No.'+str(i))
print('answer is '+label[max_index])こいつを実行すると以下のような結果が出力されます。

ほとんど正解していますがたまに間違った答えを出してしまってますね。
どうやって学習済みモデルを使用していくかイメージがつかめたでしょうか?
まぁ即席で作ったのでこんなもんでしょう。
おわりに
というわけで今回は自作したサンプル画像を使って画像分類AIモデルの構築を実演してみました。
AIモデル構築の際にぜひ参考にしてみてください。
また、今回は画像だけをAIに入力するというものでしたが、画像+その他の情報も一緒に入力することも可能です。
以下で紹介していますのでこちらもあわせてご覧ください。
【AI】複数の入力(画像+1次元データ)を持つ画像分類CNNモデル構築を実演
このように、私のブログでは様々なスキルを紹介しています。
今は仕事中で時間がないかもしれませんが、ぜひ通勤時間中などに他の記事も読んでいただけると嬉しいです。
⇒興味をもった方は【ヒガサラ】で検索してみてください。
確実にスキルアップできるはずです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント
初めてコメントさせていただきます
よろしくお願いします
この記事のサンプルプログラムを試してみたのですが、エラーとなり詰まってしまいました
申し訳ありませんがアドバイスがあればお願いします
環境はwindowsです
(大変申し訳ありませんが初心者のため何もわかっていません。場違いな質問でしたら申し訳ありません)
①
以下の記述だと読み込めないようです
from tensorflow.keras.models import Sequential
以下に変更することで読み込めるようになったようなのですが合っていますか?
from keras.models import Sequential
②実行でエラーになる
実行すると以下でエラーが発生します
何が間違っているのでしょうか?
model.add(MaxPooling2D(pool_size=(2, 2)))
Exception encountered when calling layer “max_pooling2d” (type MaxPooling2D).
Negative dimension size caused by subtracting 2 from 1 for ‘{{node max_pooling2d/MaxPool}} = MaxPool[T=DT_FLOAT, data_format=”NCHW”, explicit_paddings=[], ksize=[1, 1, 2, 2], padding=”VALID”, strides=[1, 1, 2, 2]](Placeholder)’ with input shapes: [?,128,128,1].
よろしくお願いします
以上
ご質問ありがとうございます。
全く同じことをしているのであればどちらの質問も私との環境違いから生じるものと思われます。
ですので
from tensorflow.keras.models import Sequential
が通るような環境を整えるか
from keras.models import Sequential
に適したモデル構築を行うか、ですね。
おそらく以下が同じお悩みかと思いますので御参考ください。
https://stackoverflow.com/questions/49079115/valueerror-negative-dimension-size-caused-by-subtracting-2-from-1-for-max-pool
私も始めたころはよくエラーに悩まされました(^^;)
とりあえずエラーメッセージをGoogleに放り込んでみるのが良いですよ(^^)