

こんにちは、ヒガシです。前回に引き続きLSTMのデータ加工のお話です。
前回紹介した記事では、Python上で適当な時系列データを作成し、それをLSTM用に加工していましたが、実業務においてそんなデータを使うことはまずありません。
というわけで今回は実際の業務適用をイメージして、csvファイルにまとめられている時系列データをLSTM用に加工⇒学習⇒評価という流れを実演してみようと思います。
今回も前回同様に入力、出力ともに複数個あるパターンで実施していきます。
それではさっそくやっていきましょう!
使用するサンプル時系列データの紹介
今回は以下のような時系列データを使用していきます。
一般的によくあるように、一番左の列に時刻、それより右に各時刻のデータがならんでいるものですね。
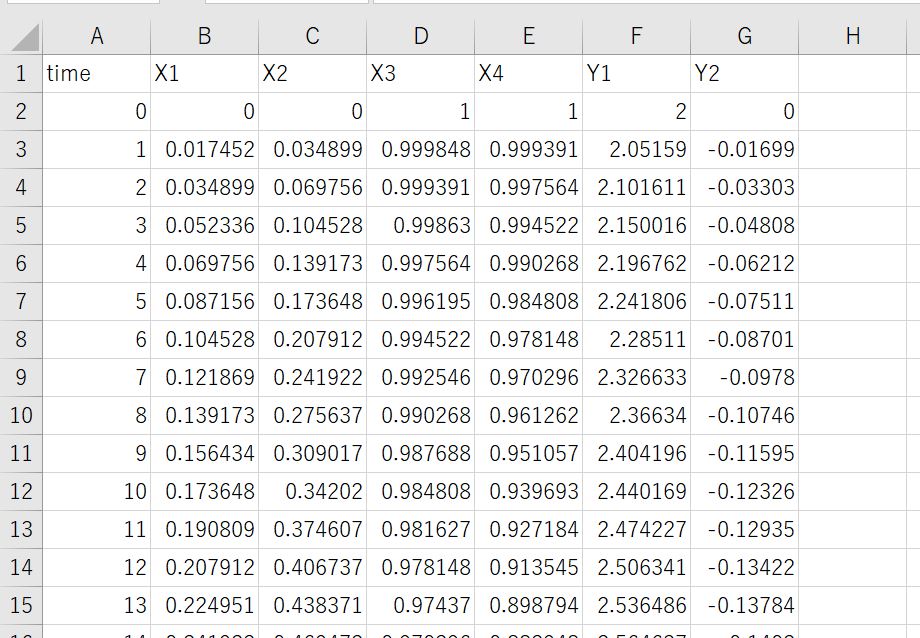
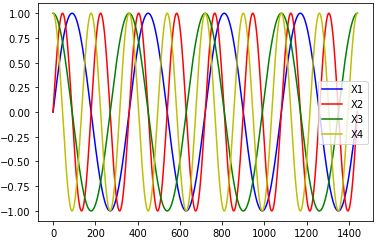
データの中身は以下のように入力(X)がSIN波、COS波、出力(Y)がそれらの合成波になっているものです。
〇入力(X)データ
〇出力(Y)データ
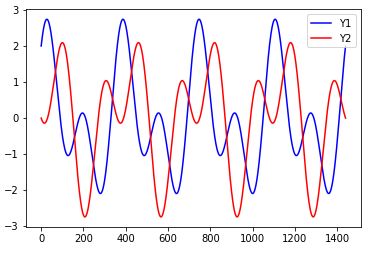
今回はこの入力データ4つから出力データ2つを予測する、という流れで実演していきます。
時系列csvデータの読み込み方法
それではさっそく実際の作業に入っていきましょう。
まずは先ほどのcsvファイルを読み込んでいきます。
今回はプログラム実行場所にあるdata_set.csvというファイルを読み込んでみます。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data_file='data_set.csv'
#csvファイルの読み込み
data=pd.read_csv(data_file).values
#時刻データ(一番左側)は使わないので除去する
data=data[:,1:]
これで先ほど紹介したX1~Y2までの時系列データが、変数dataに格納されています。
読み込んだcsvファイルデータをLSTM用に加工する
次は先ほど読み込んだデータをLSTM用に加工していきましょう。
以下がそのサンプルコードです。
#データを入力(X)4つ、出力(Y)2つに分ける
input_data=data[:,0:4]
output_data=data[:,4:6]
Xdata=[]
Ydata=[]
#LSTM用にデータ加工
look_back=5
for i in range(data.shape[0]-look_back):
Xtimedata=[]
for j in range(input_data.shape[1]):
Xtimedata.append(input_data[i:i+look_back,j])
Xtimedata=np.array(Xtimedata)
Xtimedata=Xtimedata.transpose()
Xdata.append(Xtimedata)
Ytimedata=[]
for j in range(output_data.shape[1]):
Ytimedata.append(output_data[i+look_back,j])
Ydata.append(Ytimedata)
Xdata=np.array(Xdata)
Ydata=np.array(Ydata)
これでXdata、Ydataという変数にLSTM用の入力データ、出力データが格納されています。
LSTM用のデータは(データの総組み合わせ個数, 過去分のデータ数,1つのデータの次元)という構成になっている必要がありますので、
実際に加工したデータをLSTMに入れてみる
ここまでくるともうこの記事の趣旨とは外れますが、学習⇒テストまでやってみましょう。
まずは学習です。
#ライブラリインポート
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
from tensorflow.keras.optimizers import Adam
#学習用の情報指定
Xdim=Xdata.shape[2]
Ydim=Ydata.shape[1]
validation_split_rate=0.2
#モデル構築
model = Sequential()
model.add(LSTM(4, input_shape=(look_back,Xdim)))
model.add(Dense(Ydim))
model.compile(loss="mean_squared_error", optimizer=Adam(lr=0.001))
model.summary()
#学習開始
history=model.fit(Xdata,Ydata,batch_size=16,epochs=200,validation_split=validation_split_rate)
#学習履歴のグラフ化
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
こいつを実行すると以下のグラフが出力されました。
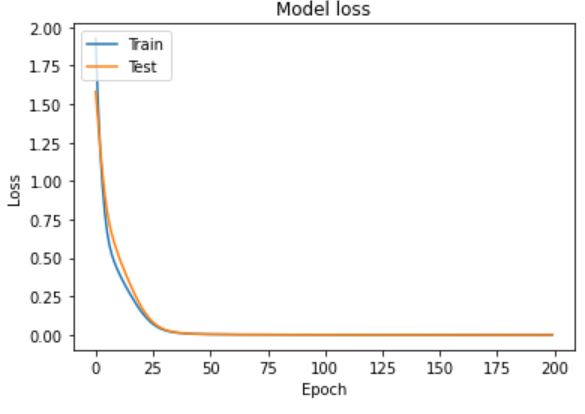
Lossが問題なく減り、学習データとテストデータの損失がほぼ一致していますね。
学習したモデルの精度を確認してみる
それでは先ほど学習させたモデルをテストしてみましょう。
#学習データから学習時にテストデータとして用いた部分を取り出す
Xdata_validation=Xdata[-int(len(Xdata)*(validation_split_rate)):]
Ydata_validation=Ydata[-int(len(Ydata)*(validation_split_rate)):]
#テスト
Predictdata = model.predict(Xdata_validation)
#テスト結果のグラフ化
plt.plot(range(0, len(Predictdata)),Predictdata[:,0], color="b", label="predict")
plt.plot(range(0, len(Ydata_validation)),Ydata_validation[:,0], color="r", label="row_data")
plt.legend()
plt.show()
kerasのvalidation_splitは指定した割合でデータの前半を学習、後半はテスト用に分割してくれていますので、同じ操作でまずは学習用、テスト用に分割します。
そしてテスト用データだけをモデルに投入し、出てきた結果をもともとのデータと比較するという流れですね。
こいつを実行すると以下の結果が得られました。
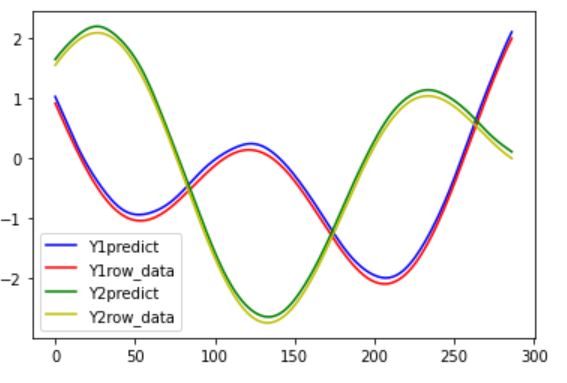
(精度が良すぎて重ねってしまいわかりにくかったので、あえてちょっと数値をずらしています。)
というわけで問題なく予測できていそうですね。
おわりに
というわけで今回は時系列データがはいっているcsvファイルからLSTM用のデータを作成⇒学習⇒テストという流れを実演してみました。
データ分析の際などにぜひご活用ください。
このように、私のブログでは様々なスキルを紹介しています。
今は仕事中で時間がないかもしれませんが、ぜひ通勤時間中などに他の記事も読んでいただけると嬉しいです。
⇒興味をもった方は【ヒガサラ】で検索してみてください。
確実にスキルアップできるはずです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント