

こんにちは、ヒガシです。今回も前回に引き続きLSTMのお話です。
※今回の記事は前回の記事の続きという位置づけです。
これまでの紹介したLSTMモデルというのは、過去の時系列データから次の時刻の予測したいデータのみを予測するというものでした。
今回紹介する内容は、次の時刻だけではなく、次の次の時刻、その次の時刻といった形でどんどん先の時刻の情報も予測するということにトライしてみようと思います。
図にすると以下のような違いです。
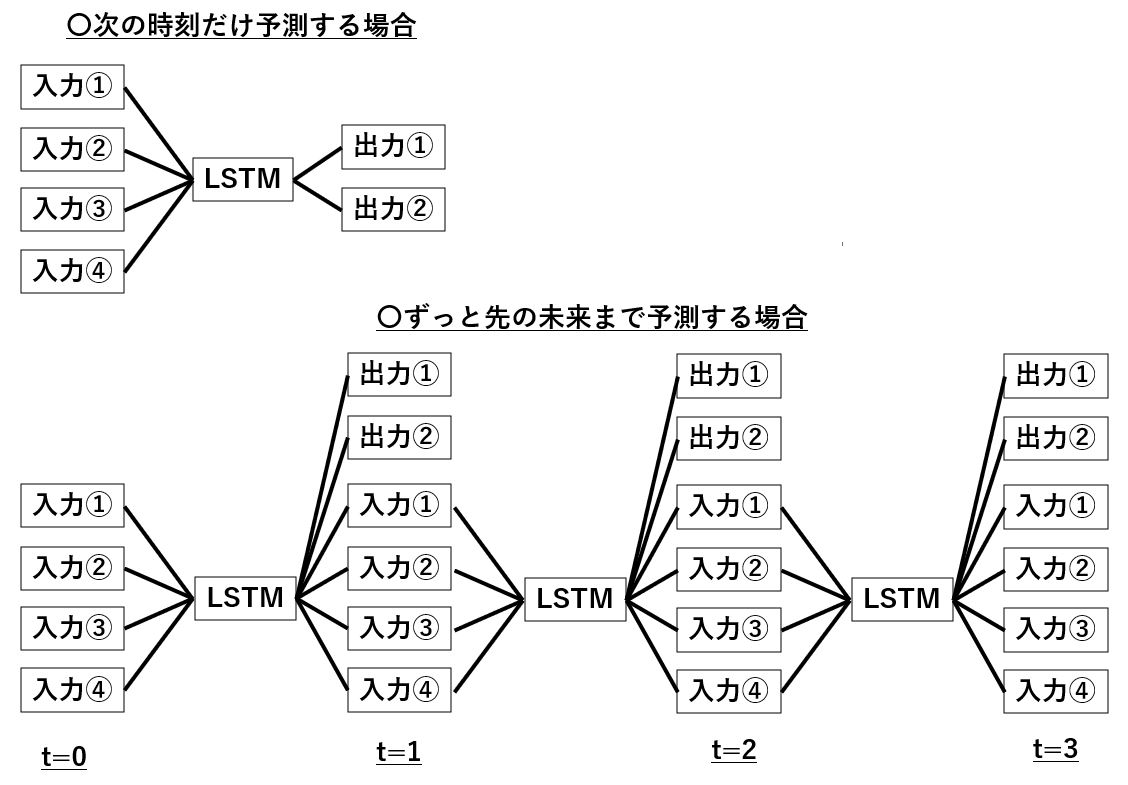
といってもこれだけではイメージしにくいとおもいますので、天気予報を例に考えてみましょう。
例えば過去一週間分の・降水・湿度・風速といった時系列情報を入力すると、明日の気温を予測できるというLSTMモデルがあったとします。
明日の気温さえわかれば良いという状況の場合、LSTMモデルに入力するデータはすでに計測されている正しいデータ(過去一週間分のデータ)になります。
しかし、明後日、明々後日の気温も予測したいといった状況の場合どうすれば良いでしょうか?
その方法の一つとして、予測したい対象である次の日の最高気温と一緒に、それを予測するための入力データも一緒に予測してしまう、ということが考えられます。
今回はこの内容を実演し、どのくらい先のデータまで正しく予測できるのかを検証してみようと思います。
前置きが長くなりましたが、それでは本題に入っていきましょう!
使用する時系列サンプルデータ
今回は前回の記事でも紹介した以下のcsvファイルを使用します。
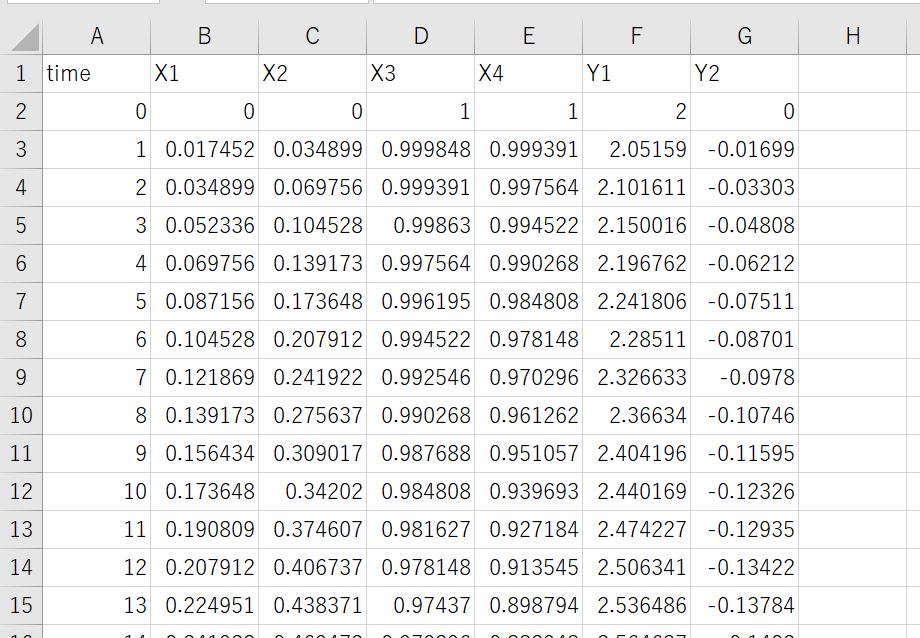
〇X1~X4を可視化した結果
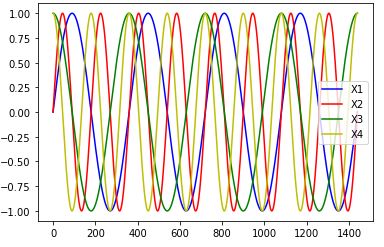
〇Y1,Y2を可視化した結果
LSTMモデルの構成としては、X1,X2,X3,X4の時系列データを入力としX1,X2,X3,X4,Y1,Y2を出力とするモデルとなります。
これで、ある時刻のX1,X2,X3,X4を入力すれば、予測したい次の時刻のY1,Y2に加え、その次の時刻を予測するためのX1,X2,X3,X4も同時に予測することができますね。
この作業を繰り返すことでずっと先の時刻のデータも予測できるというわけです。
それを図示すると以下のような感じですね。
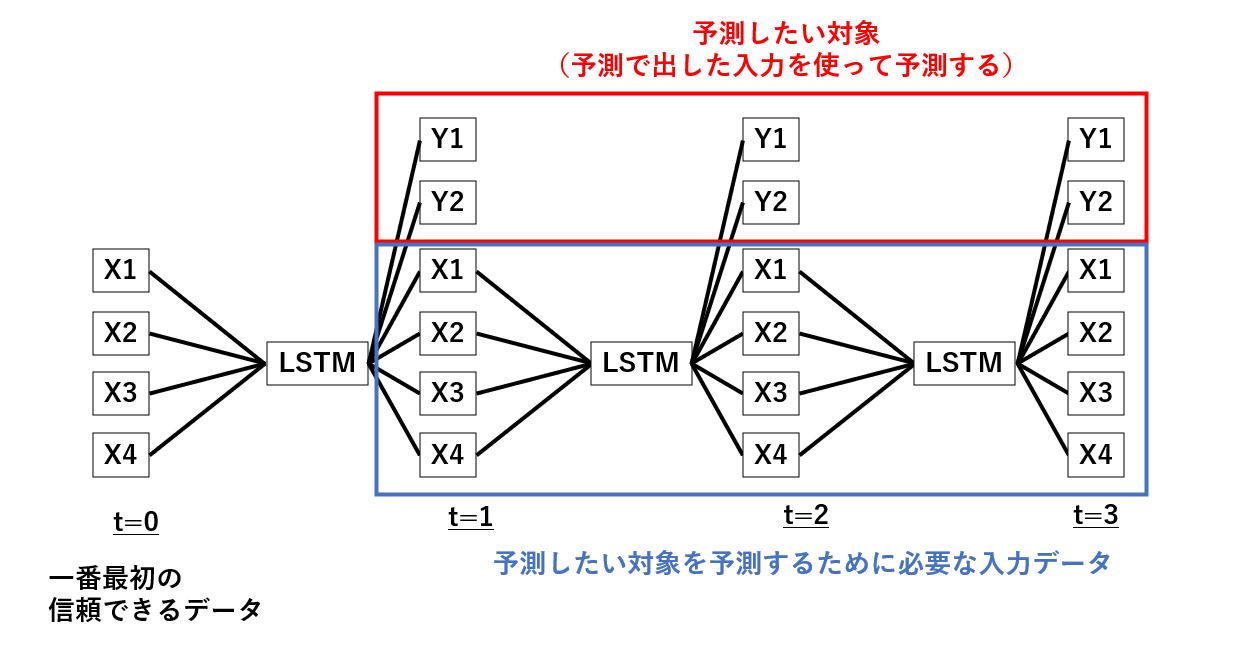
LSTMモデルの構築
それでは先ほどのデータを使って目的を満たすLSTMモデルを構築してみます。
ここは前回の記事とほとんど同じなので、サンプルコードだけ載せておきます。
#ライブラリインポート
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.layers import LSTM
from tensorflow.keras.optimizers import Adam
#データ読み込み
data_file='data_set.csv'
data=pd.read_csv(data_file).values
data=data[:,1:]
#読み込んだデータを入力、出力に分ける
input_data=data[:,0:4]
output_data=data[:,0:6]
#LSTM用に加工
Xdata=[]
Ydata=[]
look_back=5
for i in range(data.shape[0]-look_back):
Xtimedata=[]
for j in range(input_data.shape[1]):
Xtimedata.append(input_data[i:i+look_back,j])
Xtimedata=np.array(Xtimedata)
Xtimedata=Xtimedata.transpose()
Xdata.append(Xtimedata)
Ytimedata=[]
for j in range(output_data.shape[1]):
Ytimedata.append(output_data[i+look_back,j])
Ydata.append(Ytimedata)
Xdata=np.array(Xdata)
Ydata=np.array(Ydata)
#モデル構築
Xdim=Xdata.shape[2]
Ydim=Ydata.shape[1]
validation_split_rate=0.2
model = Sequential()
model.add(LSTM(4, input_shape=(look_back,Xdim)))
model.add(Dense(Ydim))
model.compile(loss="mean_squared_error", optimizer=Adam(lr=0.001))
model.summary()
#モデル学習開始
history=model.fit(Xdata,Ydata,batch_size=16,epochs=200,validation_split=validation_split_rate)
構築したモデルの精度検証
先ほど構築したモデルの精度を確認しておきましょう。
以下のコードで確認してみます。
Xdata_validation=Xdata[-int(len(Xdata)*(validation_split_rate)):]
Ydata_validation=Ydata[-int(len(Ydata)*(validation_split_rate)):]
Predictdata = model.predict(Xdata_validation)+0.01
plt.plot(range(0, len(Predictdata)),Predictdata[:,0], color="b", label="Y1predict")
plt.plot(range(0, len(Ydata_validation)),Ydata_validation[:,0], color="r", label="Y1row_data")
plt.plot(range(0, len(Predictdata)),Predictdata[:,1], color="g", label="Y2predict")
plt.plot(range(0, len(Ydata_validation)),Ydata_validation[:,1], color="y", label="Y2row_data")
plt.legend()
plt.show()※この精度検証は常に正しい入力データが入った場合の誤差です。
こんな感じでほぼビチビチに予測できている状態です。
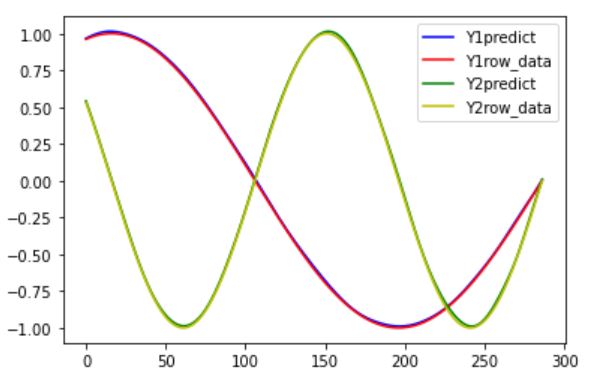
このレベルの精度ならかなり先の時刻まで予測できそうですね。
LSTMでの複数先のデータ予測コード
先ほど構築したLSTMモデルに、信頼できるに入力データを一つ投入し、出てきたデータを再度入力として利用するといった処理を繰り返すことで、すっと先の未来の情報を予測してみます。
以下がそのサンプルコードです。
Xdata_validation=Xdata[-int(len(Xdata)*(validation_split_rate)):]
Ydata_validation=Ydata[-int(len(Ydata)*(validation_split_rate)):]
new_Ydata=[]
first_input=Xdata_validation[0]
for i in range(Ydata_validation.shape[0]):
Predictdata = model.predict(np.array([first_input]))
next_input=np.concatenate([first_input,Predictdata[0,:4].reshape(1,4)],0)[1:,:]
first_input=next_input
new_Ydata.append(Predictdata)
new_Ydata=np.array(new_Ydata)
これでnew_Ydataという変数の中に最初の一つ分のデータだけを使って未来を予測した結果が入っています。
複数先の未来予測の精度確認
それでは先ほどのコードで予測した未来予測の結果を確認してみましょう。
plt.plot(range(0, len(new_Ydata)),new_Ydata[:,0,4], color="b", label="Y1predict")
plt.plot(range(0, len(Ydata_validation)),Ydata_validation[:,4], color="r", label="Y1row_data")
plt.legend()
plt.show()
plt.plot(range(0, len(new_Ydata)),new_Ydata[:,0,5], color="g", label="Y2predict")
plt.plot(range(0, len(Ydata_validation)),Ydata_validation[:,5], color="y", label="Y2row_data")
plt.legend()
plt.show()
結果以下の通り。
〇Y1の予測結果
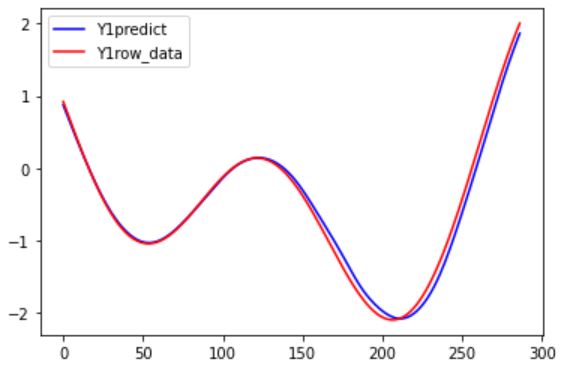
〇Y2の予測結果
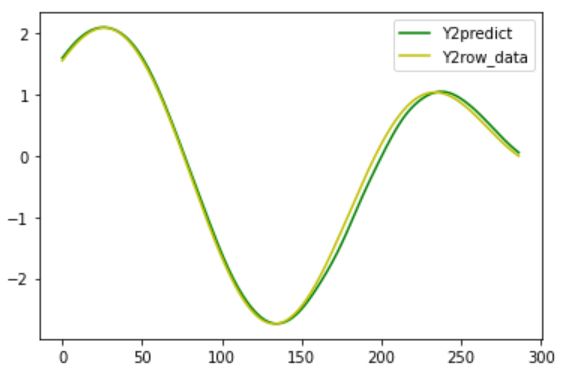
最初の方はある程度正しいデータと一致していますが、どんどん時刻が進んでいくごとに少しずつ誤差が大きくなってしまっていますね。
やはり、一回の計算でどうしても多少の誤差は生まれてしまいますから、その誤差を持ったデータを次の時刻用に入力することで、より誤差が大きくなる。これを繰り返すことでどんどん誤差が増えていってしまうのでしょうね。
とはいえまだ改善案はあるので次回はそのあたりにチャレンジしてみようとおもいます。
その結果は以下の記事でご紹介していますので、ぜひこちらもあわせてご覧ください。
【AI】LSTMでの長期未来予測2!現在との差分を予測して精度改善!
おわりに
というわけで今回はLSTMモデルを使ってずっと先の未来を予測するということにチャレンジしてみました。
結果は残念でしたが、ある程度のところまでは予測できそうですね。
次回の改善案のトライにもぜひご期待ください。
このように、私のブログでは様々なスキルを紹介しています。
今は仕事中で時間がないかもしれませんが、ぜひ通勤時間中などに他の記事も読んでいただけると嬉しいです。
⇒興味をもった方は【ヒガサラ】で検索してみてください。
確実にスキルアップできるはずです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント