


この記事ではpandasのread_csvでcsvファイルを読み込んだときのヘッダーの処理方法をいくつかご紹介していきます。
具体的には以下の画像ような複数のヘッダーを持つcsvファイルを読み込んだ際の処理方法をご紹介していきます。
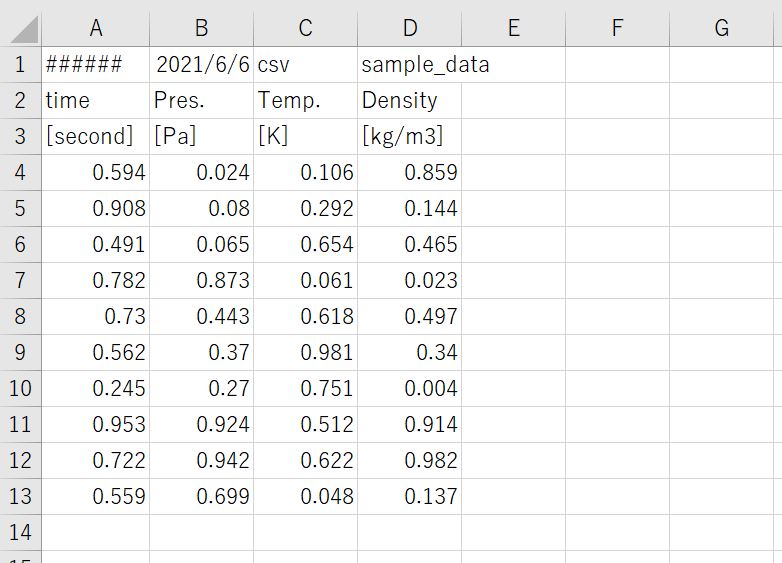
実験データなんかはよくこんな感じで出力されていますよね。
非常によく使うスキルだと思いますので、ぜひやり方をマスターしておきましょう。
それでは実際のスキル紹介に入っていきます。
pandasのread_csv時のデフォルトヘッダー処理
まずは何も考えないでpandasでcsvを読み込んでみましょう。
pandasでcsvファイルを読み込む方法は以下の通りです。
変数=pd.read_csv(‘指定ファイル名’)
以下が実際のサンプルコードです。
これで先ほど紹介したcsvファイルを読み込んでみましょう。
(先ほどのcsvファイルはsample_data.csvという名前で保存してあります。)
import pandas as pd
data = pd.read_csv('sample_data.csv')
print(data)こいつを実行すると以下の結果が出力されました。
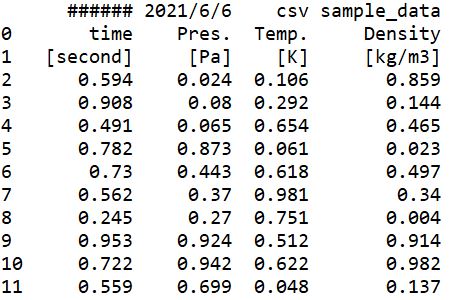
この何も指定しない場合だと、最初の1行目が勝手にヘッダーとして取り扱われているみたいですね。
(画像の一番上の行には、左端の列番号が割り当てられていないことがわかります。)
デフォルト設定値がどうなっているかわかったところで、以降はヘッダーの取り扱い方法をいろいろと変更する方法をご紹介していきます。
ヘッダーがないものとして読み込む方法
さきほど紹介したようにデフォルトでは1行目が勝手にヘッダーになってしまいます。
1行目からデータとして扱いたい場合もあるでしょうから、次はヘッダーを割り当てない方法をご紹介していきます。
以下がそのサンプルコードです。
import pandas as pd
data = pd.read_csv('sample_data.csv', header=None)
print(data)このコードの実行結果は以下のとおりです。
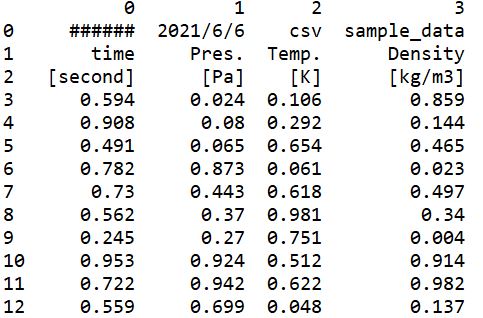
問題なくもとのcsvファイルの1行目が読み込んだデータの1行目としてあつかわれていますね。
要はヘッダーを付けたくないときは、ファイル名を指定した後にheader=NoneをつければOKというわけですね。
複数行をヘッダーとして指定する場合
このあたりから実用上よくやる処理になってきます。
最初に紹介したcsvファイルは4行目以降が実際に使いたいデータとなっています。
ですので、次は1,2,3行目をヘッダーとして読み込んでみましょう。
以下がそのサンプルコードです。
import pandas as pd
data = pd.read_csv('sample_data.csv', header=[0,1,2])
print(data)
このコードの実行結果は以下のとおりです。
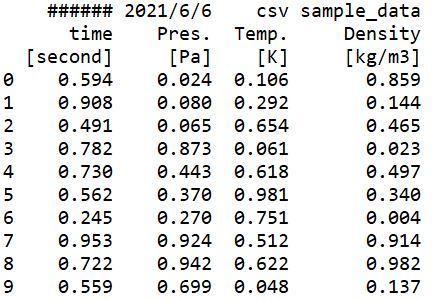
数値データが始まるところから、左端の行数番号が割り当てられていますね。
複数行をヘッダーとして取り扱いたいときは、ファイル名を指定した後にheader=[*,*,*]という形で、ヘッダー部分を指定すればOKというわけですね。
ヘッダーを1行だけ指定する場合
今回読み込むcsvファイルは2行目だけ読み込めばだいたい何のデータかわかります。
次はこの2行目だけをヘッダーとして取り扱う方法をご紹介します。
以下がそのサンプルコードです。
import pandas as pd
data = pd.read_csv('sample_data.csv', skiprows=[0,2])
print(data)
このコードの実行結果は以下のとおりです。
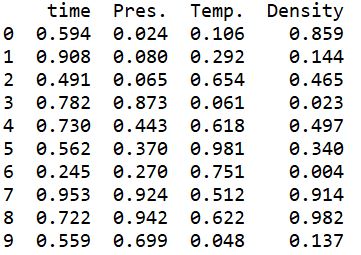
問題なく狙い通り読み込めていますね。
今回はファイル名を指定した後にskiprows=[0,2]という形で、読み込んだ際に1行目、3行目をスキップしています。
そして最初に紹介したように、pandasのread_csvはデフォルトで一番上の行がヘッダーになりますので、残された2行目が勝手にヘッダーになるわけですね。
ここは少し複雑なので一度自分で設定を変えながら実行して確認してみましょう。
ヘッダーなし&数値だけで読み込みたい場合
最後に、
「ヘッダーなんてどうでも良いから数値だけ読み込みたい」
という場合に使える方法をご紹介します。
以下がそのサンプルコードです。
import pandas as pd
data = pd.read_csv('sample_data.csv', header=None, skiprows=[0,1,2])
print(data)
このコードの実行結果は以下のとおりです。
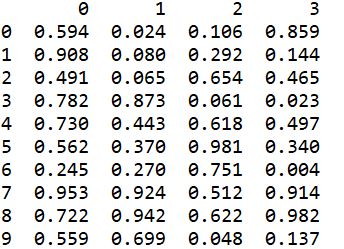
これも問題なく読み込めていますね。
要はこれまでに紹介したheader=Noneとskiprowsを組み合わせただけですね。
おわりに
というわけで今回はpandasでcsvファイルを読み込ん際のヘッダー処理の方法をいくつかご紹介しました。
データ分析の際などに非常によく使いますので、ぜひマスターしておきましょう。
このように、私のブログでは様々なプログラミングスキルを紹介しています。
今は仕事中で時間がないかもしれませんが、ぜひ通勤時間中などに他の記事も読んでいただけると嬉しいです。
⇒興味をもった方は【ヒガサラ】で検索してみてください。
確実にスキルアップできるはずです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント